|
|
OCR Zones best practice
-Remember that during day-to-day scanning, paper documents will never be presented to the scanner in the same position as when you scanned the document template. As a result, you will find that Zone OCR will be much more reliable if you allow for positioning error when drawing your zone box, by leaving white space around the reference you are trying to read.
-If your document has pre-printed boxes on it, try to exclude vertical lines from the zone to be read by OCR, as these can be interpreted as letters or numbers.
-The default Scan2x OCR functionality becomes more reliable when it is presented with a chunk of text to recognize, and not just a handful of letters. For example, to OCR the invoice number in the document at right, draw the box as shown – this will give the OCR engine enough characters to work with, while keeping the box small enough to prevent slow-down of the entire operation. See the next section for details of how to isolate the invoice number from the rest of the text.
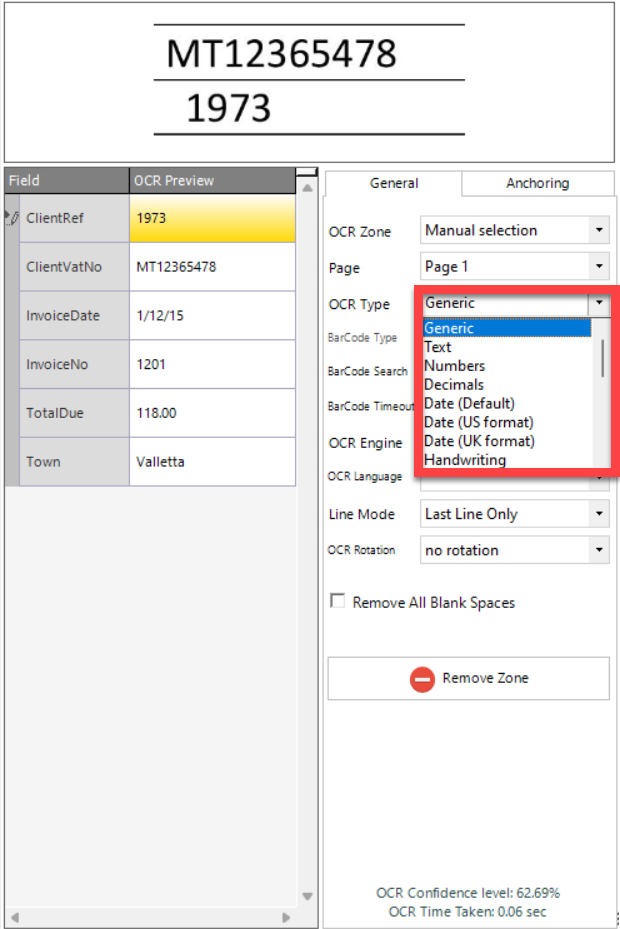
Once a metadata field has been linked to a zone for OCR, it is possible to qualify the results that you expect from the OCR operation by selecting one of the following options in the dropdown highlighted in the red box in the above screenshot:
|
Option
|
Description
|
|
Generic (Default)
|
The Generic setting accepts the entire text generated by the OCR process.
|
|
Text Only
|
Specifies that text is expected. The function therefore substitutes letters for digits where applicable, to ensure accuracy. These substitutions include lowercase “L” where 1 is read, “b” where 6 is read, “B” where 8 is read and “P” where 9 is read.
|
|
Numbers Only
|
Specifies that digits only are expected. The function therefore substitutes digits for letters where applicable, to ensure accuracy. These substitutions include 1 where lowercase “L” is read, 6 where “b” is read, 8 where “B” is read and 9 where “P” is read.
|
|
Decimals
|
Specifying this option will tell Scan2x not to eliminate the period (“.”) and comma characters from the captured text.
|
|
Date (Default)
|
Instructs Scan2x to expect text in the form of a date. The system will attempt to change the date it finds into a standardised format.
|
|
Date (US format)
|
As above, but specifies MM-DD-YY format
|
|
Date (UK format)
|
As above, but specifies DD-MM-YY format
|
|
Handwriting
|
When using the iDRS OCR Engine, you can select this option to enable handwriting recognition. Please read the additional guidelines below before attempting to recognize handwriting.
|
|
Handwriting (Boxed)
|
When using the iDRS OCR Engine, you can select this option to enable handwriting recognition of boxed letters. This is text that has been printed with individual letters in pre-printed boxes on a form. Please read the additional guidelines below before attempting to recognize handwriting.
|
|
Barcode
|
Drawing a zone around a barcode will interpret that barcode.
|
|
QR Code
|
Drawing a zone around a QR Code will interpret that QR Code.
|
|
Barcode or QR Code
|
Use this feature when documents could include either a barcode or a QR Code in the same position. This has been used where a project to scan past documents (on which barcodes were printed) together with current documents on which QR Codes are now printed.
|
|
Barcode Type
|
Use this feature when documents include a barcode, and you would like to know which specific barcode is being used in the document.
|
|
Barcode Search
|
Use this feature to specify whether you would like Scan2x to focus on BestSpeed or BestQuality when searching for a Barcode on a document.
|
|
Barcode Timeout
|
Informs Scan2x to skip finding a barcode if the set timer runs out.
|
|
Aztec Code
|
Aztec Codes are a form of 2D barcode.
|
|
Data Matrix
|
Data Matrix codes are a form of 2D barcode.
|
|
PDF417
|
PDF417 are a form of 2D barcode, commonly used by the airline industry on some boarding card formats.
|
|
ID Card MRZ
|
Instructs Scan2x to attempt to locate structured data within a Machine Readable Zone, performing all the standard Checksum controls.
Using the MRZ selection, it is possible to instruct Scan2x to search an entire zone for the presence of an MRZ. Scan2x will automatically detect this data format, isolate it from the rest of the content of the document and process it into its component parts.
|
|
Cheque MICR
|
Enables Scan2x to read the Magnetic Ink Character Recognition (MICR) data on a cheque.
|
|
Table
|
Scan2x can process data presented on a document in tabular form and split it into rows and columns. This data is saved by Scan2x in XML format for further processing by downstream systems. An example of the use of this functionality is the line item extraction of data from invoices.
Table zones can be set to adjust their position and size dynamically on the document to span content that is typically different on each document submitted. For example, a batch of invoices may vary between those containing one-line item and those containing multiple line items spanning many pages. Using the Anchor functionality to allow Scan2x to automatically detect the start and end of the table for each document, it is possible for Scan2x to accurately capture all lengths of document automatically.
|
|
Table (with headers)
|
As above, but by selecting this option you instruct Scan2x to expect the first row of the OCR'd table to be a header
|
|
Table (flipped)
|
Scan2x will process a table like the example below
.png)
and from the above will create a conventional table like the one below.
.png)
|
|
Table (with headers, flipped)
|
Scan2x will process a table like the example below
.png)
and from the above will create a conventional table like the one below.
.png)
|
|
RAW OCR Data
|
This option outputs the raw OCR Engine data for the text analysed in this OCR Zone. Data about each character recognised together with its position found in the zone is included in the output. Normally used in advanced integration projects.
When you select this option, the field you select will not return the string value of the OCR zone you specify, but rather an XML data structure of every letter found by OCR together with their position information on the page in pixels.
|
OCR Zone allows the user to either manually select an OCR zone on the document or OCRs the whole page, which puts all text on the page into a metadata field.
The OCR Engine dropdown allows the administrator to select what OCR Engine they would like to use for specific metadata fields. If one leaves the option as 'Field Default', Scan2x will then use the OCR Engine that is specified in the Scan Settings tab.
Once an OCR Engine is selected, the OCR Language option will be available. This option allows administrators to choose the language they will be OCRing.
Once the expected result of the OCR process has been defined, it is also possible to instruct Scan2x to keep the entire result or only a portion of it.
Selecting First Line Only in the drop box shown on the right in the screenshot below instructs Scan2x to populate the metadata field with the first line returned by the OCR process only, and discard the rest, while Last Line Only does the opposite. All in 1 Line tells Scan2x to put all captured text into one large string – this is commonly used to capture addresses from documents.

The OCR Rotation option allows Scan2x to OCR text that is printed vertically up or down the page. This option is only available in the full version of Scan2x.
Checking the Remove All Blank Spaces instructs Scan2x to delete all <space> characters from the OCR result. For example, the result “INV 1234” will be converted to “INV1234”.
Temporary Metadata
.png)
Checking the Use for Splitting Conditions only instructs Scan2x to only OCR that zone once for the splitting process, this will decrease the processing time.
Redaction feature
Redaction can be configured within the Manage OCR Zones section, but only under the Temporary Metadata tab. This feature functions similarly to standard OCR Zones. Users can redact content by selecting the desired area on the document through a simple click-and-drag action.
Additionally, redaction zones can be anchored to specific keywords found on the document, following the same approach used when setting up OCR Zones. This allows for consistent and dynamic redaction based on recognizable patterns or phrases within the document.
.png)
|
|